다른 사람의 Python 코드를 보다가 if__name__=='__main__'이라는 코드를 본적이 있다.
직감적으로 아~~~ 여기부터 main이구나, Python은 Entry Point를 이렇게 정의하는구나라고 생각했다.
반은 맞고 반은 틀렸다. 정확히 말하면 '현재 스크립트 파일이 실행되는 상태를 파악하기 위해 사용하는 코드' 이다.
정확한 표현은
if__name__ =='__main__'
'코드'
이다.
이 코드의 의미는 __name__ 이라는 변수 값이 '__main__' 이라면 코드를 실행하라는 뜻이다.
즉 __name__ 변수의 값이 '__main__' 이면 '코드'부터 시작하도록 하면 된다. '코드' 가 main 함수가 되는 것이다.
__name__이 변수라면 이 변수는 어디에 선언/정의되어 있는 것일까? 변수라면 어떤 값들을 가질 수 있는 것일까?
도대체 이 코드는 왜 사용하는 것일까?
__name__변수는 어디에 선언/정의 되어 있는 걸까?
__name__은 Python의 내장변수이다. Python 내부 어딘가에 선언/정의되어 있다는 뜻이다. 선언/정의되어 있는 정확한 위치는 Python Document를 찾아보면 된다.( 나도 모른다는 소리이다.)
변수라면 어떤 값들을 가질 수 있는 것일까?
__name__ 은 모듈의 이름을 저장하는 변수다. import로 모듈을 가져올 때는 __name__에 모듈의 이름이 저장되고, import가 아니라 모듈을 실행 시킬때는 __name__안에 '__main__' 이라는 값이 저장된다.
도대체 이 코드는 왜 사용하는 걸까?
Python은 모듈 단위로 실행되며 하나의 파일은 하나의 모듈이다. Python은 초기 탄생할 때 리눅스/유닉스에서 하나의 모듈, 파일로 실행, 사용했다. 그렇기 때문에 main함수가 없고 들여쓰기 하지 않는 모든 코드를 실행한다. 다만 함수나 클래스는 정의되었지만 호출되지 않는 이상 실행되지는 않는다. 사람사는게 어찌 생각한대로만 되던가...
Python은 OS의 단순 스크립터를 뛰어 넘어 광범히하게 여러군데서 사용하게 되었고 하나의 모듈, 파일 단위가 아니라 C/C++, Java 처럼 한 프로젝트에 여러개의 모듈, 파일을 가지게 되었다.
여기서 문제가 생겼다. Python은 모듈단위로 실행 시킬 수 있다면서, import로 포함하는 것도 하나의 모듈이고 이 것도 import하자마자 실행 되겠네.
이 문제를 해결하기 위해 if__name__=='__main__' 코드를 사용하는 것이다.
Python 각 모듈에
if__name__ =='__main__'
'코드'
이 코드가 있다면, 서두에서도 말했듯이 '현재 스크립트 파일이 실행되는 상태를 파악하기 위해 사용하는 코드' 이고 모듈을 import로 사용하면 __name__ 에 모듈명이 저장되기 때문에 if 구문에 False가 되어 import 한 모듈은 실행이 안되는 것이다. import를 모듈이 아니라 실행 모듈에서는 __name__에 '__main__' 이 저장되고 if 구문이 True가 되어 실행이 된다.
아래 몇 가지만 기억하자
__name__ 은 Python의 내장변수이다.
__name__ 변수는 '현재 스크립트 파일이 실행되는 상태를 파악하기 위해 사용하는 코드' 이다.
C/C++, Java를 오랫동안 해오던 나는 Python에 main함수, Entry Point가 없는 것에 대해 궁금하게 생각했다. 아니 더 정확히 말하자면 환장하겠다.
C/C++, Java는 처음 만들어질 때부터 여러 소스파일을 사용할 수 있도록 했기 때문에 Entry Point, 시작함수인 main을 따로 정해 놓았지만 Python은 처음에 개발 될 당시에는 리눅스/유닉스에서 사용하는 스크립트 언어 기반이었기 때문에 프로그램의 시작점을따로 정하지 않았다고 한다. 보통 리눅스/유닉스의 스크립트 파일은 파일 한 개로이루어진 경우가 많은데 이 스크립트 파일이 하나의 프로그램이다 보니 시작점이 따로 필요하지 않다.
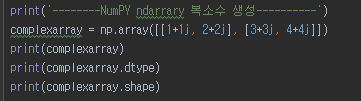
NumPY는 벡터 행렬계산을 효율적으로 처리하기 위한 모듈로 Numeric 모듈과 Numarray 모듈이 합쳐져 높은 수준의 다차원 배열 계산을 고속 및 효율적으로 처리할 수 있다. 역시 pip 로 설치할 수 있다. pip로 opencv-python을 설치할 때 numpy는 자동으로 설치가 되는데 영상을 다룰때 numpy는 꼭 필요한 lib이기 때문이다.
하지만 NumPY만으로는 무언가를 할 수는 없다. NumPY는 데이타를 가공하는 도구일 뿐이기 때문이다. NumPY를 통해 1차적으로 가공된 다차원배열의 데이타( 영상같은 )를 가지고 opencv 같이 필요한 모듈에서 사용하는 것이다.
NumPY, Scipy, Matplotlib와 opencv-python에 대해 정리를 할 것이다. 따로 Python 문법에 대해서는 언급하지 않을 것이다. python 문법은 간단하기 때문에 필요 모듈을 공부하다 보면 자연스럽게 익혀지게 될 것이다.
아래 사이트는 Python의 자료형 및 NumPy 및 영상처리를 위한 Scipy와 Matplotlib에 대한 내용이 있다.
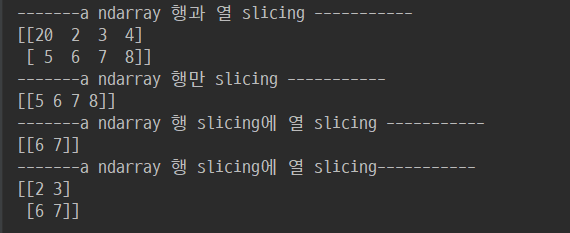
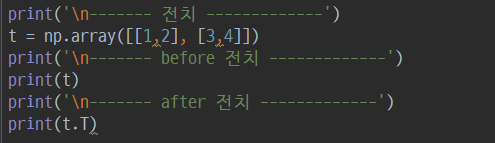
4. 인덱싱, 슬라이싱, 전치, 형태변경, 연결, 연산을 이용한 다차원 배열 현태 변경하기
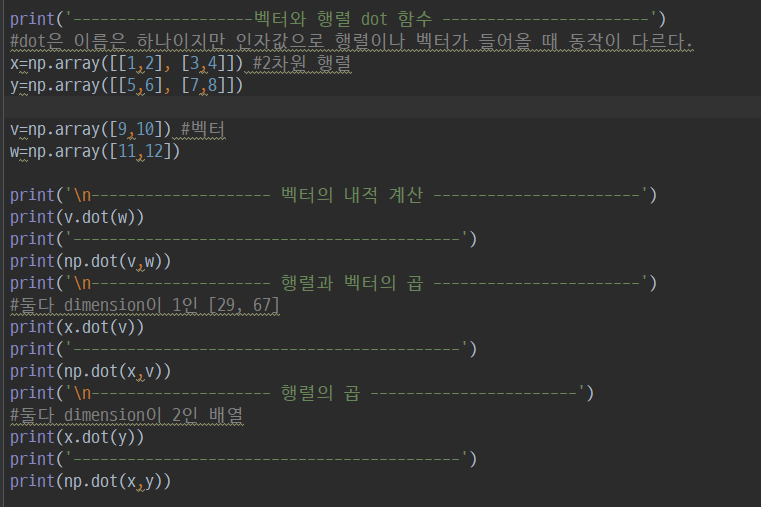
5. 브로드캐스팅, 벡터화 연산 NumPY 고급기능
순서대로 공부를 진행할 예정이다.
첫 번째로 '1. NumPY 개요'에 대해서 공부를 해보자.
NumPY는 거의 모든 Python lib 모듈을 사용하는데 있어 기본이 된다.
NumPy 존재이유
NumPY는 Pandas, Scikit-learn, Tensorflow등 데이터 사이언스 분야에서 사용되는 라이브러리들의 토대가 되는 라이브러리이다. NumPY 는 높은 수준의 데이터 분석 기능을 제공하지 않지만 NumPY를 활용해 Python상에서 표현하고 다룰 줄 알아야만 데이터 분석이라는 그 이후 단계로 나아갈 수 있다. NumPY만으로는 머신러닝을 할 수 없다. NumPY는 다차원 배열이라는 ndarray를 데이타로 나나태는 특화된 라이브러리이다. NumPY를 사용해서 데이타를 분석하거나 머신러닝 코드를 짜는게 목적이기 때문에 라이브러리로써 사용할 줄 알게 되면 된다. 다시 말해 NumPY는 다차원 배열을 나타내기 위한 라이브러리이다.
Python에는 list라는 컨테이너가 있다. 이 list안에 list를 중첩시킴으로써 다차원 배열을 나타낼 수 있다. Python의 list와 NumPY는 무엇이 다를까? Python의 list에 접근하기 위해서는 for문을 사용하고 1차원에서 2차원으로 데이터의 차원이 증가하면 반복문도 중첩되게 사용하게 되어 데이터의 차원이 증가할수록 코드는 복잡해질 수밖에 없다. NumPY를 사용하면 다차원배열을 효율적으로 다룰 수 있고 C로 구현되어 있는 NumPY보다 Python의 list가 느리다.
NumPY 사용 예
결과 값
NumPY 장점
코어부분이 C로 구현되어 동일한 연산을 하더라도 Python에 비해 속도가 빠르다.
라이브러리에 구현되어있는 함수들을 활용해 짧고 간결한 코드 작성이 가능하다.
효율적인 메모리 사용이 가능하도록 구현되어 있다.
NumPY는 다차원 배열을 내부에 구현되어 있는 메소들을 사용하여 편리하게 사용, 나타낼 수 있으며 빠르기 때문에 많이 사용된다.
ndarray가 list보다 빠른 이유
ndarrary vs list 구조
그림에서 보면 Python list에는 데이터가 들어있지 않고 데이터를 가르키는 포인터, 주소값이 들어가 있다. NumPY이는 C 배열처럼 연속적으로 데이터가 그대로 입력되어 있어 구조상으로 차이가 난다. NumPY는 이 데이터를 C 반복문으로 순회하고 Python은 Python 반복문으로 순회하기 때문에 구조적으로 언어적으로 속도의 차이가 발생한다.